
What is Information Capture and how does it benefit organizations?
![]() Information capture is the process of capturing both images and data from content. In most circles, this is known as the process of scanning, indexing, and data entry from paper documents, but it can often other sources like web submissions, faxes, emails, mobile app submissions, and more. Many enterprises aim to improve the flow of data, but run into roadblocks when it comes to inefficient manual data entry and validation steps. This is where a proven automated information capture solution from an experienced provider like PaperFree can eliminate the bottlenecks and get your data working for you.
Information capture is the process of capturing both images and data from content. In most circles, this is known as the process of scanning, indexing, and data entry from paper documents, but it can often other sources like web submissions, faxes, emails, mobile app submissions, and more. Many enterprises aim to improve the flow of data, but run into roadblocks when it comes to inefficient manual data entry and validation steps. This is where a proven automated information capture solution from an experienced provider like PaperFree can eliminate the bottlenecks and get your data working for you.
Studies have shown that approximately 80% of business data is trapped inside of unstructured, unmanaged documents - the most difficult type of document to automatically capture and digitize. However, PaperFree's advanced capture solutions bridge this hurdle by automatically searching content for key words and phrases to establish context and then extracting important business information accurately. Then, data is validated utilizing multiple sources such as database lookups, regular expressions, direct integration to other systems, and more. The end result is perfected data that is passed on to your core business applications quickly, efficiently, and inexpensively. Plus, PaperFree offers specialty solutions to expand the capabilities of your information capture system, from inline redaction, check processing, and even system monitoring.
Curious to learn more about how OCR, ICR, OMR, and ODR work? Learn more at our Recognition Explainer
The solutions PaperFree provides utilize technologies like intelligent document recognition (IDR), Advanced Extraction (ICR/OCR) and variations of non-templated free-form process to extract your mission critical information from virtually any kind of incoming document. The use of automation technologies to capture, classify, and extract information from content can provide the following benefits:
Speed
Information Capture systems offer faster processing which results in reduced labor costs
Accuracy
More accurate processing through the use of business rules and automated validations
Do More
Capture of more information which provides even more benefit to the organization when utilized in business analytics or other big data initiatives
Efficiency
Capturing at the point of origin - ensures that information enters the enterprise quickly and efficiently and is utilized easier and potentially even farther downstream than ever before
A single unified capture platform for all incoming information into the enterprise is finally well within reach. The days of departmental information silos can be a thing of the past. A future where information is captured across departments and utilized wherever and whenever it is needed most can be achieved through the use of intelligent capture technology. To learn more about how information capture solutions from PaperFree can help you achieve faster more efficient processing of your information give us a call today.
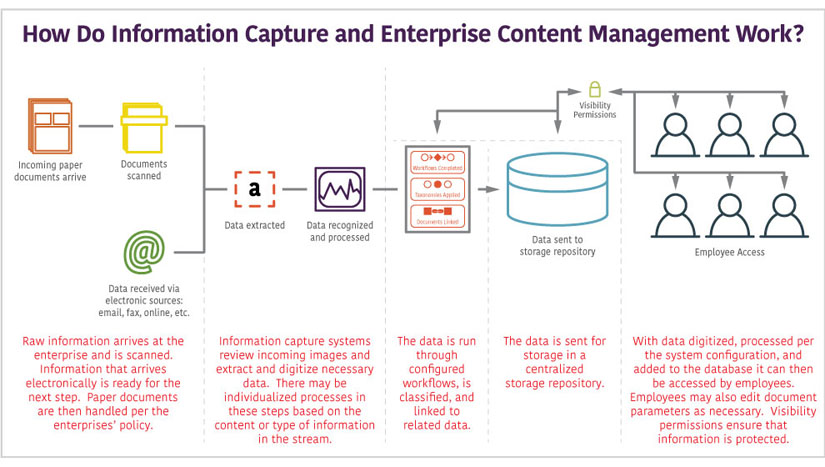
How does it work?
- An information capture workflow needs raw data to run. Typically, this raw data arrives in paper form by mail or courier, but it can also be sourced from email inboxes, faxes, or other configured electronic inputs.
- Then, data is brought into the system by scanning the paper documents and importing the electronic files into a processing queue.
- Once digital images of the documents exist, their information is analyzed and business-critical information such as account numbers, names, and addresses are extracted and digitized.
- This digital information is then exported to a customized automated workflow where it is processed and is routed to the appropriate operators if needed.
- Once processing is complete the scanned invoice image as well as the information about its transaction are exported to a storage repository. Here, it can be stored for compliance or can be easily pulled up by operators for customer service, management, or training needs.

Solutions for any Document Type
Information Capture solutions from PaperFree are equipped to seamlessly process all types of documents:
- Structured - information is provided in a consistent, repeatable, location like in a credit card application, insurance claim form, or income tax form for example.
- Semi-structured - information is provided in various locations but often utilizing the same key information in the same general area or arrangement like what is found on invoices, purchase orders, or checks for example.
- Unstructured - information is found anywhere with no consistency of location or arrangement like what is found on correspondence, contracts, or loan documents.
Key Benefits:
- Centralized storage – documents and other information are stored in one location for easy maintenance and access.
- Fast access – access digital information quickly and group related documents.
- Taxonomies – classify documents for easier lookup.
- Speed processing – feed scanned data into backend systems for automated processing..
- Save money – with only one repository to manage there are no costs to maintain paper files.